Puppeteer爬取Eletron官网文档并保存为pdf格式
原创2022年8月2日
为什么要做这个小爬虫?
说起来是个艰辛的路程...
当我接触到
electron时,被这强大的用处深深吸引!但是官网确老是抽风!
时不时的不能翻译成中文,
恰好有一天,发现能翻译 中文了,就萌生了一个使用
puppeteer将文档爬取下来保存!
开始
npm i puppeteer
config.js
保存pdf 需要在无头模式下进行headless: true,
// 配置文件
module.exports = {
// chrome配置文件
chrome: {
headless: true,
// 忽略 自动化提示
ignoreDefaultArgs: ["--enable-automation"],
// 浏览器路径
// executablePath: "",
// 浏览器用户数据存放地址
userDataDir: "./userDataDir",
slowMo: 30,
defaultViewport: {
width: 1536,
height: 730,
},
},
};
PdfUtils.js
const fs = require("fs");
const path = require("path");
module.exports = class PdfUtils {
constructor(page) {
this.page = page;
// 文档总菜单类名(!唯一)
this.menuUlLi = ".theme-doc-sidebar-item-category";
// menu的菜单名 类名
this.menuUlLiA = ".menu__list-item-collapsible >a";
// 每个子菜单的类名
this.li_a = ".menuLink_aa1l";
}
/**
* 获取 this.menuUlLi 的每一个子菜单的菜单名
* @returns {Promise<Array>}
*
*/
async getMenuName() {
const menuName = await this.page.$$eval(this.menuUlLiA, (as) =>
as.map((a) => a.innerText)
);
return menuName;
}
/**
* 处理 getMenuName 返回的数据
* 将数组中的每一项通过空格分开,再使用 - 合并
* @returns {Promise<Array>}
*/
async getMenuNameHandle() {
const menuName = await this.getMenuName();
const menuNameHandle = menuName.map((item) => {
return item.split(" ").join("-");
});
return menuNameHandle;
}
/**
* 返回当前页面主菜单下面的每个子菜单的长度
* @returns
*/
async getMenuLength() {
const menuLength = await this.page.$$eval(
this.menuUlLi,
(lis) => lis.length
);
return menuLength;
}
/**
* 点击每一个菜单,返回当前菜单的子菜单长度
*/
async clickMenu() {
const menuLength = await this.getMenuLength();
for (let i = 1; i < menuLength; i++) {
try {
if (i >= menuLength) return;
// 等待1秒
await this.page.waitForTimeout(1000);
await this.page.click(`${this.menuUlLi}:nth-child(${i + 1})`);
} catch (error) {
console.log(i);
}
}
}
/**
* 在页面内执行js代码,返回一个对象 包含a 的href和innerText
* @returns {Promise<Array>}
*/
async getHrefInfo() {
const menuHref = await this.page.$$eval(this.li_a, (as) =>
as.map((a) => {
return {
//
menu: a.parentElement.parentElement.parentElement.childNodes[0].childNodes[0].innerHTML
.split(" ")
.join("-"),
href: a.href,
innerText: a.innerText.split(" ").join("-"),
};
})
);
return menuHref;
}
/**
* 根据url 通过 / 分割,获取最后一个字符串
* @param {string} url
* @returns {string}
*/
getUrlLastStr(url) {
const urlArr = url.split("/");
const lastStr = urlArr[urlArr.length - 1];
return lastStr;
}
/**
* 检测文件名是否合法
* 不合法则正则替换为合法的文件名
* @param {string} name
* @returns {string}
*/
checkFileName(name) {
const reg = /[\/:*?"<>|]/g;
const newName = name.replace(reg, "");
return newName;
}
/**
* 通过 url 保存PDF
* @param {*} obj
*/
async getPdf(obj) {
const { menu, href, innerText } = obj;
console.log([menu, href, innerText]);
await this.page.goto(href);
// 判断文件夹是否存在,不存在则创建
const dir = this.checkFileName(menu);
if (!fs.existsSync(dir)) {
fs.mkdirSync(dir);
}
const urlLastStr = this.getUrlLastStr(href);
await this.page.pdf({
path: `./${dir}/${this.checkFileName(innerText)}.pdf`,
format: "A4",
// printBackground: true,
});
// 判断是否下载完成
const isExist = fs.existsSync(`./${dir}/${innerText}.pdf`);
if (isExist) {
console.log(`${innerText}下载完成`);
}
}
};
app.js
const puppeteer = require("puppeteer");
const { chrome } = require("./config");
const PdfUtils = require("./PdfUtils");
(async () => {
const browser = await puppeteer.launch(chrome);
const page = await browser.newPage();
await page.goto("https://www.electronjs.org/zh/docs/latest/api/app");
const pdfUtils = new PdfUtils(page);
const menuLength = await pdfUtils.getMenuLength();
console.log(menuLength);
const menuName = await pdfUtils.getMenuNameHandle();
console.log(menuName);
await pdfUtils.clickMenu();
const menuHrefArr = await pdfUtils.getHrefInfo();
console.log(menuHrefArr);
// 开始下载
for (let i = 0; i < menuHrefArr.length; i++) {
console.log("---");
await pdfUtils.getPdf(menuHrefArr[i]);
// 判断是否全部下载完毕,如果下载完毕则关闭浏览器
if (i === menuHrefArr.length - 1) {
await browser.close();
}
}
})();
执行
node app.js
等待片刻,即可得到electron的pdf文档
下载完毕的目录
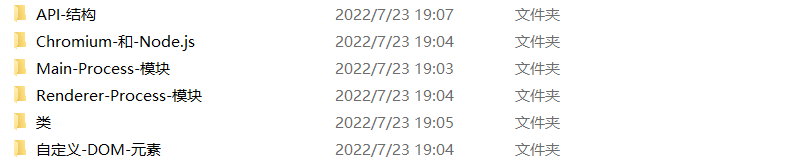
目录文件
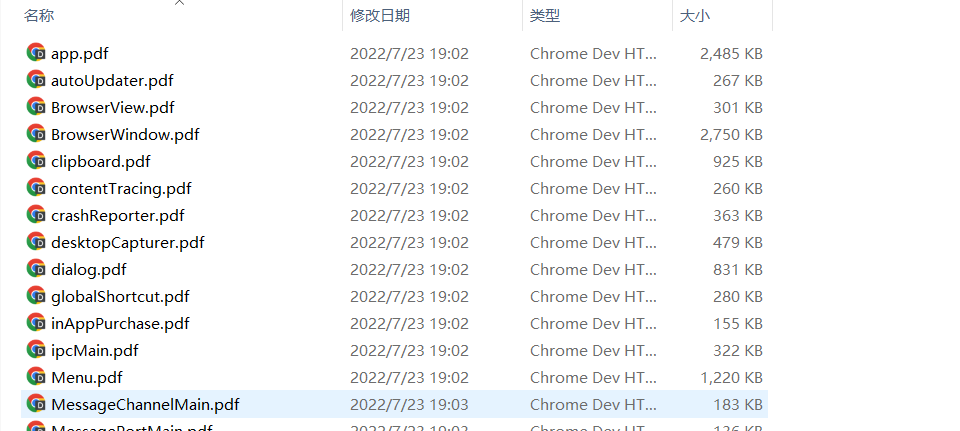
文件
学习分享,大佬勿喷!
Loading...